
Using Druid to fight ad fraud

This article written by Raigon Jolly, TrafficGuard’s Head of Analytics originally appeared on Imply.
TrafficGuard helps some of the world’s biggest digital advertisers and agencies protect their ad spend from fraud. In an environment like online advertising where volume and quality fluctuate, our clients need access to reliable reporting in real-time to allow them to optimise their ad campaigns with current insights. To achieve real-time reporting means processing 1000s of queries each second with high concurrency and billions of transactions daily, each with 80+ dimensions and 30+ measures. This challenge, compounded by our fast growth, is what lead us to Druid.
The need to scale
When TrafficGuard started over 3 years ago, our analytics were based on a combination of AWS Redshift and MySQL (AWS Aurora). We used Redshift to serve historical queries and Aurora for more real-time queries. We stored our raw data in S3 and every 15 minutes, we would pre-process this data through ETL jobs using Talend. The subsequent processed data would be written to Aurora, and periodic jobs migrated data from Aurora to Redshift.
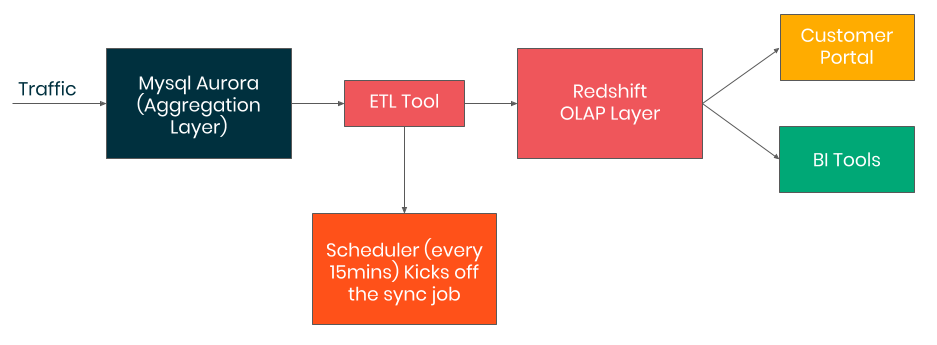
When our data set was small and simple (15 dimensions and 1 measure), this legacy architecture functioned without issue. However, as our data grew in scale and as we added more dimensions and measures, the legacy architecture started suffering from scaling and performance challenges. As our data set approached 60 dimensions, queries began to slow down significantly, often taking minutes to complete. Furthermore, the legacy architecture was primarily batch based and it took over 20 minutes to surface new insights. For a fraud analytics system, latency of ingest and queries is critical, and we needed less delays to be able to explore our data and take meaningful action.
Evaluating and selecting Druid
As we considered modernizing our solution, we looked at several different solutions. We considered Apache Kylin, but determined it did not have the real-time ingest capabilities we desired. We also evaluated Elasticsearch, but found its capabilities for measuring user experience, attrition, and retention were not on par with analytic databases. We even considered migrating our entire workload to Redshift, but the lack of streaming ingestion, limited support for real-time analytics, and high cost of deployment steered us to further consider our options.
Druid came onto our radar through word-of-mouth of other companies in similar spaces that found success with the project, including Airbnb, Metamarkets, and many more. In our PoC, we found that Druid scaled easily to handle 60+ dimensions. Furthermore, we were able to connect Druid directly to AWS Kinesis and build the end-to-end streaming analytics stack required.
After selecting Druid as our next generation real-time analytics engine, we partnered with Imply because of their engineering understanding as the the creators of Druid, and because of their deep understanding of problems in our space.
Working with Imply Cloud allowed us to focus less on Druid engineering and infrastructure management, and more on getting value from our stored data. By removing the burden of infrastructure management, we have been able to bring innovations in our core offering to market much faster.
Running in production
Today, we run Druid as a core component of our streaming analytics stack. Imply’s Pivot is our internal operations UI, and we have custom applications developed on top of Druid as well. All of our applications and visualizations are now interactive, snappy, and all data is ingested in real-time, much to the delight of TrafficGuard’s clients.
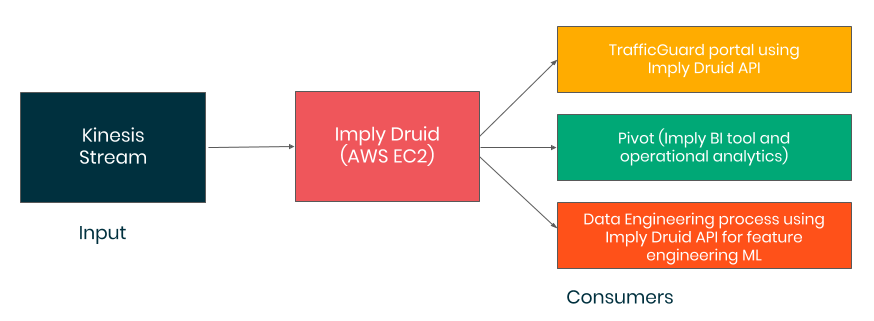
We currently have 3 datasets across 2 product lines in Druid that ingest real-time streaming data from Kinesis. The largest data set has 95 dimensions and 63 measures. Druid does a wonderful job of compressing data, so there has been a steep decline in how much data we have to store in Druid versus the raw amount.
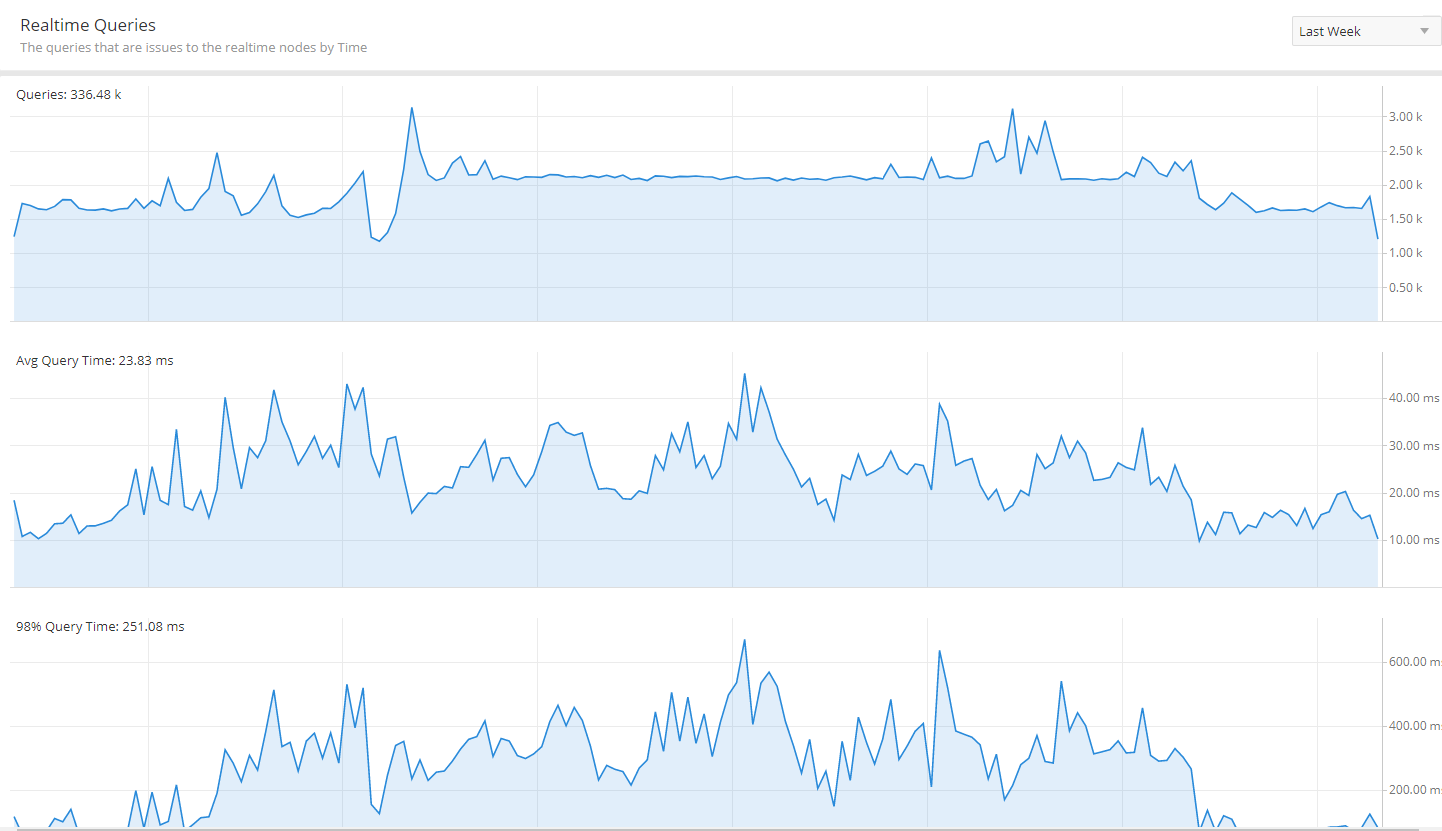
Although there are still some rough edges to work out, such as maintaining 99 percentile query latencies of less than 5 seconds on extremely high cardinality dimensions, we are confident in our choice of technology.
Looking to the future
Upcoming initiatives include integrating Druid with our machine learning and anomaly detection systems and processes. We are also greatly expanding our set of visualisations used to analyse data in internal tools.
We are constantly innovating new ways to get further ahead of these fraud operations and continue to protect our clients. With Druid, we have found an ideal analytics engine and we are excited to partner with Imply to realise Druid’s full potential in TrafficGuard’s analytics stack.
Get started - it's free
You can set up a TrafficGuard account in minutes, so we’ll be protecting your campaigns before you can say ‘sky-high ROI’.

Explore More Blogs



Subscribe
Subscribe now to get all the latest news and insights on digital advertising, machine learning and ad fraud.


