Machine learning for fraud prevention keeps TrafficGuard agile

This article was first published by TechTarget.
In the fraud detection field, machine learning has become a necessary tool for organizations seeking an advantage. Though applying machine learning technology reads like a simple statement, mastering it requires strong company-wide commitment and proper AI frameworks.
One digital ad fraud detection company, TrafficGuard, has embraced the possibilities of machine learning.
Raigon Jolly, Head of Analytics and Data Science at TrafficGuard, and his team are working with real-time fraud detection and reporting across cloud environments to reduce friction between data and actionable insights on a large scale, but their transition to machine learning use was not without obstacles.
Organizational buy-in
In fraud detection, balancing innovation across machine learning implementations, while maintaining your company’s existing machine learning and data structures, can be difficult. In order to overcome challenges, there must be big organizational buy-in.
Spending a great deal of time building an organizational culture that supports and drives machine learning initiatives involves laying the groundwork of communication and culture and working hard to keep all teams pointing in the right direction throughout development and implementation of machine learning. Raigon said:
[Building a supportive culture] is critical to ensure we have the input, insight and buy-in from different teams and stakeholders across the business with varying levels of technical understanding.
For many companies, the process of adopting machine learning has to be incremental. TrafficGuard launched with a strong machine learning component and had to build slowly and steadily as the environment changed and time advanced.
The challenge of collaboration and knowledge transfer across teams when working on rapid development cycles was difficult, Jolly said. But building an organizational culture goes a long way in overcoming this challenge. If everyone takes machine learning into consideration from the outset of new development, then the process can be simplified.
“We have an extensive set of artefacts of this culture where data assets, schema, lineage, data flow and process flow are defined and continuously maintained,” Jolly said.
These ensure that as new incremental developments in AI and machine learning are made, there are standards to guide them and consistency and control as we build on our capabilities.
Using machine learning in fraud detection
In TrafficGuard’s case, machine learning algorithms have been implemented in order to facilitate the detection of invalid traffic and ad fraud in digital advertising engagements. Its use of unsupervised learning is directed for use as anomaly detection and similarity detection.
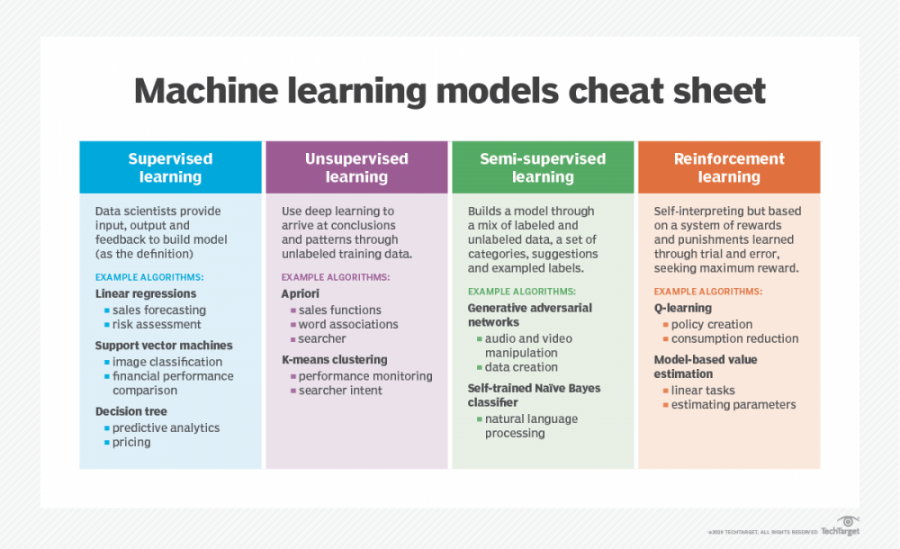
Machine learning implementation has been to combat the ever-changing atmosphere of fraud attempts. Across the board, even with rudimentary tactics, perpetrators can circumvent the rules that many companies put in place to stop invalid traffic, Jolly said.
Over time, ad fraud has become more sophisticated, with some invalid activity on the surface, appearing similar to human activity.
After the initial employee buy-in, companies need to win over the trust of their employees and teams in targeted machine learning, as well as from users. Creating a black box is not an option anymore as the general desire and regulatory need for interpretability have risen.
Jolly’s team identified the most important features and correlations of features to encode these into rules forming invalidation reasons. These result in each invalidated transaction having an accompanying reason for invalidation and making the models more interpretable and auditable. Giving reasons behind decisions lets users better understand the criteria being used by the machine learning algorithms.
Machine learning requires proper training
An obstacle for organizations like TrafficGuard to deploying machine learning is that it can be time-consuming to operationalize. With machine learning algorithms, intense training must be undertaken before they can be utilized to any effect.
Relevant data must be first identified and then selected and prepared. From here, the algorithm must be tuned, and the model is then trained over a period that could range from hours to weeks.
“Where you can build and implement a rule to stop invalid traffic in minutes, machine learning takes a much longer time to build, prepare data, train, test, deploy and then monitor on an ongoing basis,” Jolly said.
And, if the data quality is not up to viable standards, then this lengthy process can be all for nothing. The alternative, however, can be implemented with a little delay but is incapable of producing similar results to a properly trained machine learning model. Organizations must understand which process fits best for their application. Jolly said:
"A rule is much faster and easier to implement but will never give us the reliability and precision that machine learning delivers."
Get started - it's free
You can set up a TrafficGuard account in minutes, so we’ll be protecting your campaigns before you can say ‘sky-high ROI’.
At TrafficGuard, we’re committed to providing full visibility, real-time protection, and control over every click before it costs you. Our team of experts leads the way in ad fraud prevention, offering in-depth insights and innovative solutions to ensure your advertising spend delivers genuine value. We’re dedicated to helping you optimise ad performance, safeguard your ROI, and navigate the complexities of the digital advertising landscape.

Explore Other News



Subscribe
Subscribe now to get all the latest news and insights on digital advertising, machine learning and ad fraud.


